You probably shouldn't bother with (free tier) Github LFS
TL;DR, think twice about using GitHub LFS if you don't want to pay money. This post originally had a more incendary title.
- posted:
Some exposition
Git LFS is an extension to Git which improves the experience of working with “large” files, which otherwise tend to quickly bloat the size of your repo and slow down operations. It does this by:
- storing a “pointer” to the large file(s) (essentially a sha256 hash) in the Git repo
- storing the actual file separately on a “Git LFS server”
- using a
.gitattributessmudge filter to make this indirection (mostly) transparent to the user.
So, the repository size is kept down, and users only need to download large files for the ref they are checking out, while still keeping Git’s workflow and guarantees. Most git-as-a-service platforms also support acting as a Git LFS server, including GitHub.
I help run a niche site for fans of compact tools and toolkits. It’s a simple static site, which lives in a repo hosted on Github, and is deployed to Github pages. It’s fairly image heavy - almost every page has at least one image, and the working copy weighs just under 300MB (at the time of writing).
We initially tracked all the images in Git LFS - the repo was nice and small and operations were snappy. This worked totally fine for a while, until I got an email:
We wanted to let you know that you’ve used 80% of your data plan for Git LFS on the organization tinytoolkit. No immediate action is necessary, but you might want to consider purchasing additional data packs to cover your bandwidth and storage usage
…
Current usage as of 01 Oct 2024 11:42PM UTC:
Bandwidth: 0.8 GB / 1 GB (80%)
Storage: 0.28 GB / 1 GB (28%)
Less than 2 hours later, this hit 100%, and 9 days later:
Git LFS has been disabled on the organization tinytoolkit because you’ve exceeded your data plan by at least 150%. Please purchase additional data packs to cover your bandwidth and storage usage
What this meant, in practice, is that any Git pulls from the repository1 would fail at the point of trying to download LFS files:
Updating files: 100% (168/168), done.
Downloading content/manifesto/Spreadsheet.jpg (154 KB)
Error downloading object: content/manifesto/Spreadsheet.jpg (b806f42): Smudge error: Error downloading content/manifesto/Spreadsheet.jpg (b806f420c5e4c457c93daa2761368cf441a894eb36f4d240b403657c49ecc277): batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access.
Errors logged to '<snip>/tinytoolkit/.git/lfs/logs/20241016T012502.058559.log'.
Use `git lfs logs last` to view the log.
error: external filter 'git-lfs filter-process' failed
fatal: content/manifesto/Spreadsheet.jpg: smudge filter lfs failed
The “purchase more data packs” means paying GitHub $5/month to increase the bandwidth limit to 50GB.
So what happened?
We were well below our “storage” limit, but had exceeded the “bandwidth” limit. We use Github Actions to build and deploy the site, which for every deployment would checkout a copy, and with it download all the LFS-stored files. So given the circa-300MB checkout plus some activity of users pulling and pushing to the repo was more than enough to blow past the 1GB bandwidth limit.
Why do I think this sucks
To be clear, I appreciate that this is a free service. But that said, I think the free tier limits for Github LFS are worse than useless:
First of all, equal storage and bandwidth quotas don’t make much sense. You will almost always be using much more bandwidth than you do storage so long as a decent chunk of your LFS-stored files are referenced in the head ref of your repository (I.E. they’re “in use”). It’s not directly comparable, but VPS provider offerings typically have bandwidth quotas several orders of magnitude larger than the disk quotas - and for good reason.
Second, once you do hit this limit, your files are essentially held ransom - you
can’t download any new files you may not have locally, and by default the .zip archive
available via the repo’s page doesn’t include LFS files, just the pointers to them.
There is an option in repository settings to include Git LFS objects in
archives, but this seems to have mysteriously disappeared for us with our
exceeded quota. Not greyed out with an explanatory message, just totally gone.
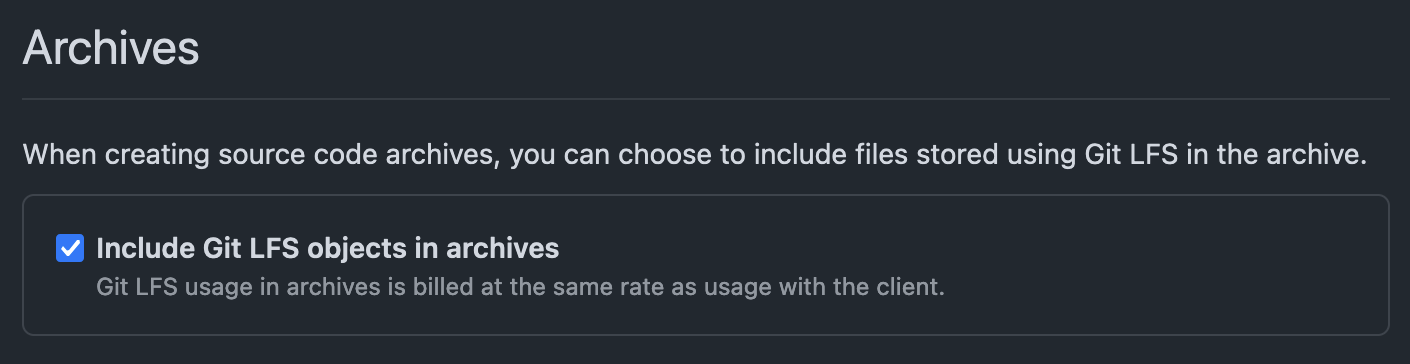
- The elusive setting that we were missing
The workaround, and how we exfiltrated our LFS files without paying GitHub $52, was by:
- Forking the repo
- Enabling the aforementioned option in the fork’s settings (which, equally mysteriously, is present for the fork…)
- Downloading a zip archive of the main branch
Third and foremost, you get essentially unlimited bandwidth if you just store your large files in directly in Git. GitHub strongly recommends keeping repos below 5GB, and will send you an email if “your repository excessively impacts [their] infrastructure”3 but they explicitly state that they’ll try to be flexible.
The quota and the enforcement of it completely discourages use of Git LFS with GitHub for free tier users, which given it’s in GitHub’s interests to make this an attractive and useful feature seems silly to me.
What would make me think this is less silly
GitHub could:
- Up the free tier bandwidth limit to a more useful and realistic value
- Allow repository owners to download their files as an exit from LFS, without having to jump through undocumented hoops
- Actually warn you in the quota emails that LFS access would be disabled entirely
Again, I know that I’m criticising a free service here, but relative to the rest of what GitHub offers for free this stands out as being quite unfriendly and awkward.
Ok, bye!
-
Technically speaking, “any git pulls or pushes which, as a part of doing so caused
git lfsto try to download or upload a file” ↩︎ -
Okay sure, or waiting for up to a month for the quota to reset ↩︎
-
https://docs.github.com/en/repositories/working-with-files/managing-large-files/about-large-files-on-github#repository-size-limits ↩︎